LLM programming intro series:
Series
Focus: In a series of articles, we will demonstrate the programming models supported by LllamaIndex. This is meant for technical software architects, developers, LLMOps engineers as well as technical enthusiasts. We provide you with actual working code so you can copy it and use it as you please.
Links
| Link | Purpose |
| https://www.llamaindex.ai/ | Main website |
| https://docs.llamaindex.ai/en/stable/ | Documentation website |
Objective of this code sample
In this code sample, we will create a Python script that interacts with the LlamaIndex’s OpenAI module. The script begins by checking if an OpenAI API key is present in the environment. If found, it initializes two instances of the OpenAI client, one for the model GPT-3.5 Turbo and another for GPT-4, with the API key set for both. Each client is used to send a series of chat messages predefined in the script, which simulate a conversation asking for travel advice to Paris. The messages include initial system instructions and user queries. After sending these messages, the script captures and processes the responses from both GPT models. It asynchronously makes these API calls and collects responses, adding subsequent messages that prompt the models to summarize the travel advice. Finally, the script measures and outputs the elapsed time for these operations, alongside the models’ responses, demonstrating the performance and interaction capabilities with different versions of the GPT models within the LlamaIndex framework.
Learning objectives
2. Try out a simple design pattern. Try out how to use the async api. Introduce you to asyncio built in python package. Note keywords async in front of main() and asyncio.run(main()).
3. Set you up for more advanced concepts in future articles.
We begin with importing the packages…
# Note1: make sure to pip install llama_index.core before proceeding
# Note2: make sure your openai api key is set as an env variable as well.
# Import required standard packages
import asyncio
import time
import os
# Import required LlamaIndex Subpackages
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
Helper function that checks if the key is present as an env variable
# helper function
def check_key() -> bool:
# Check for the OpenAI API key in the environment and set it
# Setting in env is the best way to make llama_index not throw an exception
if "OPENAI_API_KEY" in os.environ:
print(f"\nOPENAI_API_KEY detected in env")
return True
else:
return False
Use the helper function check_key() to get the api key. If you do not have one, you can get it here: https://platform.openai.com/api-keys
async def main():
if check_key():
openai_client_gpt_3_5_turbo = OpenAI(model="gpt-3.5-turbo")
openai_client_gpt_3_5_turbo.api_key = os.environ["OPENAI_API_KEY"]
openai_client_gpt_4 = OpenAI(model="gpt-4")
openai_client_gpt_4.api_key = os.environ["OPENAI_API_KEY"]
else:
print("OPENAI_API_KEY not in env")
exit(1) # Exit if no API key is found
# Define the GPT 3.5 chat messages to initiate the chat
messages_3_5 = [
ChatMessage(role="system", content="You are a helpful AI assistant."),
ChatMessage(role="user", content="Tell me the best day to visit Paris. Then, elaborate.")
]
# Define the GPT4 chat messages to initiate the chat
messages_4 = [
ChatMessage(role="system", content="You are a helpful AI assistant."),
ChatMessage(role="user", content="Tell me the best day to visit Paris. Then, elaborate.")
]
Here we are using the asynchronous method of calling the LI APIs. Each call to “create_task” will immediately return. However, execution will resume at the next line only after the two lines with “await” complete.
# timed section
# Get the current time
start_time = time.time()
# Asynchronously call both GPT-3.5-turbo and GPT-4
response_3_5_task = asyncio.create_task(openai_client_gpt_3_5_turbo.achat(messages_3_5))
response_4_task = asyncio.create_task(openai_client_gpt_4.achat(messages_4))
# Wait for both responses
response_3_5 = await response_3_5_task
response_4 = await response_4_task
messages_3_5.append(ChatMessage(role="assistant", content=str({response_3_5.message.content})))
next_prompt_3_5 = ChatMessage(role="user", content="Summarize it in 30 words.")
messages_3_5.append(next_prompt_3_5)
messages_4.append(ChatMessage(role="assistant", content=str({response_4.message.content})))
next_prompt_4 = ChatMessage(role="user", content="Summarize it in 30 words.")
messages_4.append(next_prompt_4)
# Asynchronously call both GPT-3.5-turbo and GPT-4
response_3_5_task = asyncio.create_task(openai_client_gpt_3_5_turbo.achat(messages_3_5))
response_4_task = asyncio.create_task(openai_client_gpt_4.achat(messages_4))
# Wait for both responses
response_3_5 = await response_3_5_task
response_4 = await response_4_task
# Get the end time
end_time = time.time()
In this final step, we print out the responses from the LLM. We also print out the time it took to get a run completed.
# Calculate the elapsed time in seconds
elapsed_time = end_time - start_time
# Format the elapsed time to two decimal places
formatted_time = "{:.2f}".format(elapsed_time)
# Print the FINAL responses with labels
print("\nResponse from GPT-3.5-turbo:")
print(response_3_5)
print("\nResponse from GPT-4:")
print(response_4)
# Print the formatted time
print(f"Elapsed time: {formatted_time} seconds")
if __name__ == "__main__":
asyncio.run(main())
We are working on getting you a Jupyter notebook version of this code. Also, an easy way for you to get this code from Github. We will also be publishing a YouTube series of videos that go over this material and then some more. Please stay tuned.
# # Sample Output, your results will vary
# OPENAI_API_KEY detected in env
# Response from GPT-3.5-turbo:
# assistant: The best time to visit Paris is in spring or fall for mild weather, fewer crowds, blooming flowers, autumn foliage, cultural events, and local experiences.
# Response from GPT-4:
# assistant: The best time to visit Paris is during spring (April-June) or fall (September-November) due to mild weather and fewer crowds. However, personal preferences and tolerance for crowds can influence the ideal time.
# Elapsed time: 15.30 seconds
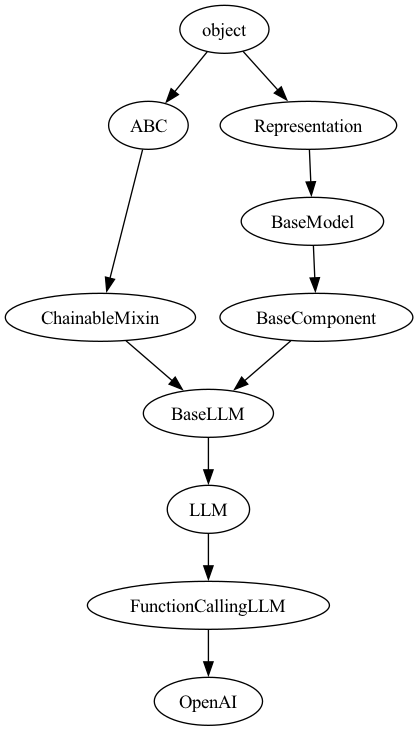
Here is the object hierarchy behind the two key classes used.