LLM programming intro series:
Series
Focus: In a series of articles, we will demonstrate the programming models supported by LllamaIndex. This is meant for technical software architects, developers, LLMOps engineers as well as technical enthusiasts. We provide you with actual working code so you can copy it and use it as you please.
Links
| Link | Purpose |
| https://www.llamaindex.ai/ | Main website |
| https://docs.llamaindex.ai/en/stable/ | Documentation website |
Objective of this code sample
This Python sample illustrates the application of asynchronous programming techniques to interact with OpenAI models, utilizing the llama_index package. The script ensures the presence of an OpenAI API key, initializes API clients, and manages asynchronous communications with both the GPT-3.5-turbo and GPT-4 models. The core objective is to demonstrate efficient asynchronous API interaction, showcasing how non-blocking calls and concurrent response processing can significantly improve performance and responsiveness in applications that integrate LLMs.
Learning objectives
2. Try out a simple design pattern of a single prompt (using PromptTemplate) and a single response. Try out how to use the async stream api. Introduce you to the concepts behind streaming, especially the async version of it.
3. Set you up for more advanced concepts in future articles.
Demo Code
The code begins by importing necessary modules such as time, os, and asyncio, and specific classes from the llama_index package. It initializes two OpenAI client objects for the models GPT-3.5-turbo and GPT-4, setting the stage for their later use in sending prompts and receiving responses.
# Note1: make sure to pip install llama_index.core before proceeding
# Note2: make sure your openai api key is set as an env variable as well.
# Import required standard packages
import time
import os
import asyncio
from llama_index.llms.openai import OpenAI
from llama_index.core.prompts import PromptTemplate
check_key function checks if the OpenAI API key is set in the environment. If found, it prints a confirmation message and returns True; otherwise, it returns False.
print_chunks is an asynchronous function that prints the response chunks as they are received. It iterates over the response asynchronously, ensuring non-blocking behavior.
def check_key() -> bool:
# Check for the OpenAI API key in the environment and set it
# Setting in env is the best way to make llama_index not throw an exception
if "OPENAI_API_KEY" in os.environ:
print(f"\nOPENAI_API_KEY detected in env")
return True
else:
return False
async def print_chunks(response, label):
async for chunk in response:
print(f"{label}: {chunk}", end="", flush=True)
# it will print interleaved output from gpt35 client and the gpt4 client
Within the main() function, the script first ensures the API key is set. It then prepares a PromptTemplate with a predefined query. Asynchronous tasks are created and dispatched to send this prompt to both models. The responses are awaited, and once received, they are processed in chunks through another set of asynchronous tasks using print_chunks, which prints each part of the response as soon as it’s available.
async def main():
if check_key():
openai_client_gpt_3_5_turbo = OpenAI(model="gpt-3.5-turbo")
openai_client_gpt_3_5_turbo.api_key = os.environ["OPENAI_API_KEY"]
openai_client_gpt_4 = OpenAI(model="gpt-4")
openai_client_gpt_4.api_key = os.environ["OPENAI_API_KEY"]
else:
print("OPENAI_API_KEY not in env")
exit(1) # Exit if no API key is found
prompt_template = PromptTemplate("You are a helpful AI assistant. Tell me the best day to visit Paris. Then, elaborate.")
start_time = time.time()
response_3_5_task = asyncio.create_task(openai_client_gpt_3_5_turbo.astream(prompt=prompt_template))
response_4_task = asyncio.create_task(openai_client_gpt_4.astream(prompt=prompt_template))
response_3_5 = await response_3_5_task
response_4 = await response_4_task
task_3_5 = asyncio.create_task(print_chunks(response_3_5, "GPT-3.5"))
task_4 = asyncio.create_task(print_chunks(response_4, "GPT-4"))
await asyncio.gather(task_3_5, task_4)
After processing the responses, the script calculates and prints the elapsed time, demonstrating the efficiency of the asynchronous operations.
end_time = time.time()
elapsed_time = end_time - start_time
formatted_time = "{:.2f}".format(elapsed_time)
print(f"\nElapsed time: {formatted_time} seconds")
if __name__ == "__main__":
asyncio.run(main())
Sample Output
The final output is demonstrated in a commented section, showing interleaved responses from the two different models, providing a clear example of how responses are handled concurrently.
PARTIAL OUTPUT SHOWN HERE FOR DEMO PURPOSES...
#here is a sample output. It has been truncated for brevity.
# OPENAI_API_KEY detected in env
# GPT-3.5: GPT-3.5: TheGPT-3.5: bestGPT-3.5: dayGPT-3.5:
# toGPT-3.5: visitGPT-3.5: ParisGPT-3.5: isGPT-3.5:
# subjectiveGPT-3.5: andGPT-3.5: canGPT-3.5: varyGPT-3.5:
# dependingGPT-3.5: onGPT-3.5: personalGPT-3.5: preferencesGPT-3.5: .GPT-3.5:
# <truncated>
# GPT-4: mostGPT-4: ofGPT-4: yourGPT-4: tripGPT-4: .GPT-4:
# Elapsed time: 14.01 seconds
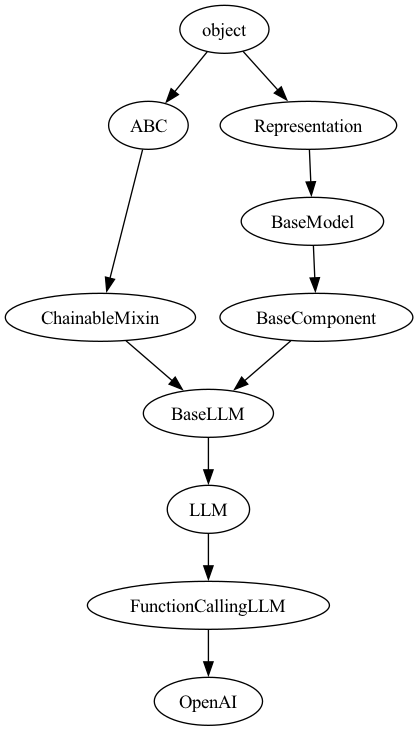
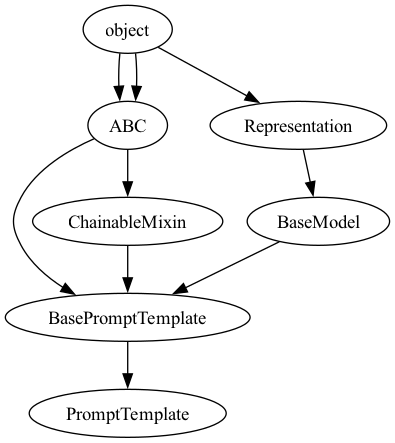
Here is the class hierarchy behind the two key classes used.
Class hierarchy of PromptTemplate Class
Class hierarchy of OpenAI Class