LLM programming intro series:
Series
Focus: In a series of articles, we will demonstrate the programming models supported by LllamaIndex. This is meant for technical software architects, developers, LLMOps engineers as well as technical enthusiasts. We provide you with actual working code so you can copy it and use it as you please.
Links
| Link | Purpose |
| https://www.llamaindex.ai/ | Main website |
| https://docs.llamaindex.ai/en/stable/ | Documentation website |
Objective of this code sample
This Python sample illustrates the application of streaming programming techniques to interact with OpenAI models, utilizing the llama_index package. The script ensures the presence of an OpenAI API key, initializes API clients, and makes synchronous, streaming call in turn to the GPT-3.5-turbo and GPT-4 models.
When a client invokes a synchronous API to interact with an LLM like GPT-3.5, it waits for the LLM to generate the entire response before the call returns. This wait time can vary significantly, typically from a few seconds to potentially minutes, depending on the complexity and length of the response. Synchronous calls are beneficial for scenarios where subsequent steps in an application depend entirely on the completion data from the API, such as tool calling, archiving to file, post-processing, or agentic interactions where the response must be evaluated before proceeding.
In a streaming API call, the client begins receiving data incrementally as soon as the first part of the output is available from the LLM, rather than waiting for the entire completion. This approach is useful for displaying real-time results to users, such as in chat applications or interactive sessions where immediate feedback enhances user experience. It allows the application to process and possibly respond to parts of the data while still receiving further data, which can be critical for maintaining engagement in real-time applications.
Learning objectives
2. Try out a simple design pattern which you can then adapt to your specific use case.
3. Set you up for more advanced concepts in future articles.
Demo Code
# Note1: make sure to pip install llama_index.core before proceeding
# Note2: make sure your openai api key is set as an env variable as well.
# Import required standard packages
import time
import os
from llama_index.core.prompts import PromptTemplate
from llama_index.llms.openai import OpenAI
def check_key() -> bool:
# Check for the OpenAI API key in the environment and set it
# Setting in env is the best way to make llama_index not throw an exception
if "OPENAI_API_KEY" in os.environ:
print(f"\nOPENAI_API_KEY detected in env")
return True
else:
return False
def main():
if check_key():
openai_client_gpt_3_5_turbo = OpenAI(model="gpt-3.5-turbo")
openai_client_gpt_3_5_turbo.api_key = os.environ["OPENAI_API_KEY"]
openai_client_gpt_4 = OpenAI(model="gpt-4")
openai_client_gpt_4.api_key = os.environ["OPENAI_API_KEY"]
else:
print("OPENAI_API_KEY not in env")
exit(1) # Exit if no API key is found
# Get the current time
start_time = time.time()
# prompt = PromptTemplate("Please write a random name related to {topic}.")
prompt = PromptTemplate("You are a helpful AI assistant. Tell me the best day to visit Paris. Then, elaborate.")
response_3_5 = openai_client_gpt_3_5_turbo.stream(prompt)
# Print the incremental responses
for chunk in response_3_5:
print(chunk, end="", flush=True)
response_4 = openai_client_gpt_4.stream(prompt)
# Print the incremental responses
for chunk in response_4:
print(chunk, end="", flush=True)
After processing the responses, the script calculates and prints the elapsed time.
# Get the end time
end_time = time.time()
# Calculate the elapsed time in seconds
elapsed_time = end_time - start_time
# Format the elapsed time to two decimal places
formatted_time = "{:.2f}".format(elapsed_time)
# Print the formatted time
print(f"Elapsed time: {formatted_time} seconds")
if __name__ == "__main__":
main()
Sample Output
PARTIAL OUTPUT SHOWN HERE FOR DEMO PURPOSES...
# here is a sample output. It has been truncated for brevity.
# OPENAI_API_KEY detected in env
# The best day to visit Paris is subjective and can vary depending on personal preferences.
# However, many people consider spring (April to June) and fall (September to November) to
# be the best times to visit Paris. During these seasons, the weather is mild, the city is
# less crowded with tourists, and you can enjoy the beautiful blooming flowers in
# the spring or the colorful foliage in the fall.
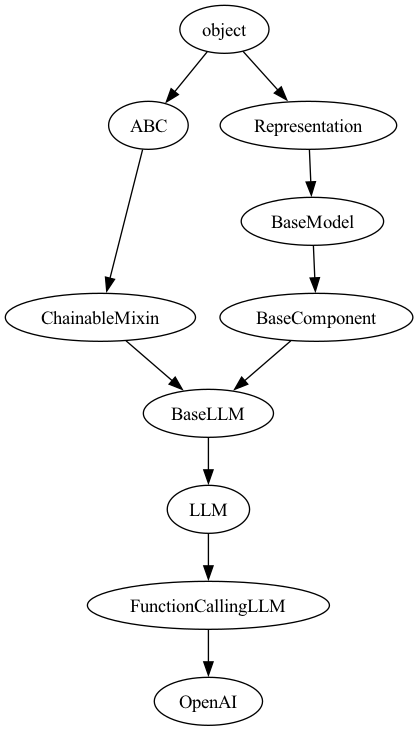
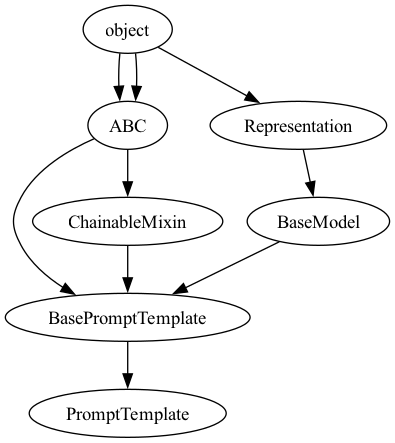
Here is the class hierarchy behind the two key classes used.
Class hierarchy of PromptTemplate Class
Class hierarchy of OpenAI Class