LLM programming intro series:
Series
Focus: In a series of articles, we will demonstrate the programming models supported by LllamaIndex. This is meant for technical software architects, developers, LLMOps engineers as well as technical enthusiasts. We provide you with actual working code so you can copy it and use it as you please.
Links
| Link | Purpose |
| https://www.llamaindex.ai/ | Main website |
| https://docs.llamaindex.ai/en/stable/ | Documentation website |
Objective of this code sample
In this code sample, we will create a Python script that interacts with LlamaIndex’s OpenAI module using a stream-based approach. The script begins by checking if an OpenAI API key is present in the environment. If found, it initializes two instances of the OpenAI client, one for the GPT-3.5 Turbo model and another for the GPT-4 model, with the API key set for both. Each client is used to send a series of predefined chat messages, simulating a conversation asking for travel advice to Paris. These messages include initial system instructions and user queries. After sending these messages, the script captures and processes the responses from both GPT models in a synchronous manner, leveraging the stream chat design pattern. This approach ensures that responses are received and displayed incrementally, enhancing real-time interaction. Finally, the script measures and outputs the elapsed time for these operations, alongside the models’ responses, demonstrating the performance and interaction capabilities with different versions of the GPT models within the LlamaIndex framework.
Learning objectives
2. Try out a simple design pattern. Try out how to use the stream api. Introduce you to the concepts behind streaming.
3. Set you up for more advanced concepts in future articles.
Demo Code
This section imports the necessary standard Python packages (time and os) and specific subpackages from LlamaIndex. The OpenAI class is used to interact with OpenAI’s language models, and ChatMessage is used to structure the chat messages.
# Note1: make sure to pip install llama_index.core before proceeding
# Note2: make sure your openai api key is set as an env variable as well.
# Import required standard packages
import time
import os
# Import required LlamaIndex Subpackages
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
Helper function that checks if the key is present as an env variable. The check_key function checks if the OPENAI_API_KEY is set in the environment variables. If the key is found, it prints a message and returns True; otherwise, it returns False.
# helper function
def check_key() -> bool:
# Check for the OpenAI API key in the environment and set it
# Setting in env is the best way to make llama_index not throw an exception
if "OPENAI_API_KEY" in os.environ:
print(f"\nOPENAI_API_KEY detected in env")
return True
else:
return False
Use the helper function check_key() to get the api key. If you do not have one, you can get it here: https://platform.openai.com/api-keys
Two lists of ChatMessage objects are created, one for each model (GPT-3.5-turbo and GPT-4). These messages initiate the chat with the system role setting the context and the user role asking a specific question.
def main():
if check_key():
openai_client_gpt_3_5_turbo = OpenAI(model="gpt-3.5-turbo")
openai_client_gpt_3_5_turbo.api_key = os.environ["OPENAI_API_KEY"]
openai_client_gpt_4 = OpenAI(model="gpt-4")
openai_client_gpt_4.api_key = os.environ["OPENAI_API_KEY"]
else:
print("OPENAI_API_KEY not in env")
exit(1) # Exit if no API key is found
# Define the GPT 3.5 chat messages to initiate the chat
messages_3_5 = [
ChatMessage(role="system", content="You are a helpful AI assistant."),
ChatMessage(role="user", content="Tell me the best day to visit Paris. Then, elaborate.")
]
# Define the GPT4 chat messages to initiate the chat
messages_4 = [
ChatMessage(role="system", content="You are a helpful AI assistant."),
ChatMessage(role="user", content="Tell me the best day to visit Paris. Then, elaborate.")
]
The current time is recorded before and after sending the chat messages to both models. The stream_chat method sends the messages and starts receiving responses.
The responses from both models are printed as they are received. The stream_chat method returns chunks of the response, which are printed incrementally.
# Get the current time
start_time = time.time()
# Synchronously (blocking call made serially) call both GPT-3.5-turbo and GPT-4
response_3_5 = openai_client_gpt_3_5_turbo.stream_chat(messages_3_5)
response_4 = openai_client_gpt_4.stream_chat(messages_4)
# Get the end time. Essentially response begins as soon as first chunk of text
# starts to stream back to us
end_time = time.time()
In this final step, we print out the responses from the LLM. We also print out the time it took to get a run completed.
# Print the incremental responses
for chunk in response_3_5:
print(chunk.delta, end='')
# Print the incremental responses
for chunk in response_4:
print(chunk.delta, end='')
# Calculate the elapsed time in seconds
elapsed_time = end_time - start_time
# Format the elapsed time to two decimal places
formatted_time = "{:.2f}".format(elapsed_time)
# Print the formatted time
print(f"\nElapsed time (first chunk return): {formatted_time} seconds")
if __name__ == "__main__":
main()
We are working on getting you a Jupyter notebook version of this code. Also, an easy way for you to get this code from Github. We will also be publishing a YouTube series of videos that go over this material and then some more. Please stay tuned.
PARTIAL OUTPUT SHOWN HERE FOR DEMO PURPOSES...
OPENAI_API_KEY detected in env
The best day to visit Paris can vary depending on your preferences and interests. However, many people find that visiting Paris during the spring (April to June) or fall (September to November) offers pleasant weather, fewer crowds, and beautiful scenery with blooming flowers or colorful autumn foliage.
During these seasons, you can enjoy outdoor activities like picnicking along the Seine River, exploring the city's parks and gardens, and strolling through charming neighborhoods without feeling overwhelmed by tourists.
Additionally, visiting Paris on weekdays rather than weekends can help you avoid long lines at popular attractions and experience a more relaxed atmosphere in the city.
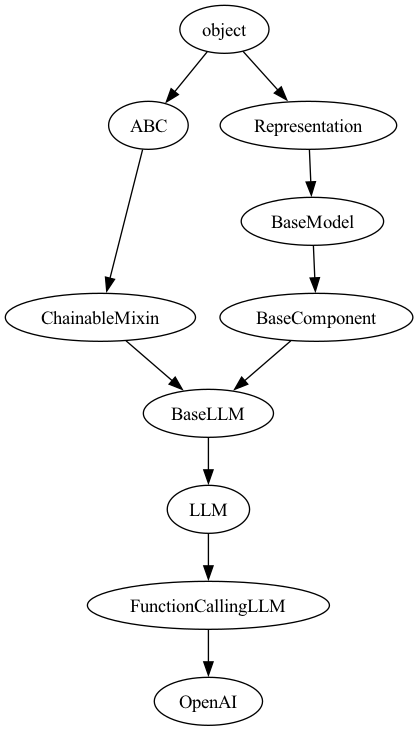
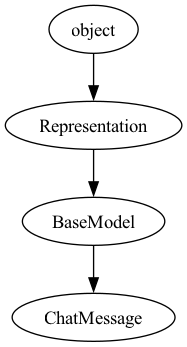
Here is the class hierarchy behind the two key classes used.
Class hierarchy of ChatMessage Class
Class hierarchy of OpenAI Class